

“One of the most typical mistakes in large-scale data projects is losing sight of the biases that may skew the insights you extract.”– James Kobielus
On the topics of Big Data, and Data Science, I have interviewed James Kobielus, IBM Big Data Evangelist.
RVZ
Q1. What kind of companies generate Big Data, besides the Internet giants?
James Kobielus: Big data isn’t something you “generate.” Rather, the term refers to the ability to achieve differentiated value from advanced analytics on trustworthy data at any scale. In other words, it’s a best practice, not a specific type of data or even a specific scale of data (measured in volume, velocity, and/or variety).
When considered in this light, you can identify big data analytic applications in every industry. Every C-level executive has strategic applications of big data. Here are just a smattering:
- Chief Marketing Officers have been the prime movers on many big data initiatives that involve Hadoop, NoSQL, and other approaches. Their primary applications consist of marketing campaign optimization, customer churn and loyalty, upsell and cross-sell analysis, targeted offers, behavioral targeting, social media monitoring, sentiment analysis, brand monitoring, influencer analysis, customer experience optimization, content optimization, and placement optimization
- Chief Information Officers use big data platforms for data discovery, data integration, business analytics, advanced analytics, exploratory data science.
- Chief Operations Officers rely on big data for supply chain optimization, defect tracking, sensor monitoring, and smart grid, among other applications.
- Chief Information Security Officer run security incident and event management, anti-fraud detection, and other sensitive applications on big data.
- Chief Technology Officers do IT log analysis, event analytics, network analytics, and other systems monitoring, troubleshooting, and optimization applications on big data.
- Chief Financial Officers run complex financial risk analysis and mitigation modeling exercises on big data platforms.
Q2. What are the most challenging problems you are facing when analysing Big Data?
James Kobielus: Searching for actionable intelligence in big data involves building and testing advanced-analytics models against large volumes of complex data that may be flowing in at high velocities.
At these scales, it’s easy to get overwhelmed in your analysis unless you automate the end-to-end processes of extracting intelligence at scale. Automation can also help control the cost of managing a growing volume of algorithmic models against ever expanding big-data collections. The key processes that need automating are data discovery, profiling, sampling, and preparation, as well as model building, scoring, and deployment.
Q3. How do you typically handle them?
James Kobielus: Automating the modeling process will boost data scientist productivity by an order of magnitude, freeing them from drudgery so that they can focus on the sorts of exploration, modeling, and visualization challenges that demand expert human judgment. Data scientists can accelerate their modeling automation initiatives by following these steps:
- Virtualize access to data, metadata, rules, and predictive models, as well as to data integration, data warehousing, and advanced analytic applications through a BI semantic virtualization layer;
- Unify access, governance, orchestration, automation, and administration across these resources within a service-oriented architecture;
- Explore commercial tools that support maximum automation of model development, scoring, deployment, and execution;
- Consolidate, accelerate, and deepen predictive analytics through integration into big-data platforms with scalable in-database execution; and
- Migrate existing analytical data marts into multidomain big-data platforms with unified data, metadata, and model governance within service-oriented virtualization framework.
Q4. What are in your experience the typical mistakes made in large scale data projects?
James Kobielus: One of the most typical mistakes in large-scale data projects is losing sight of the biases that may skew the insights you extract.
Even if you accept that a data scientist’s integrity is rock-solid, intentions pure, skills stellar, and discipline rigorous, there’s no denying that bias may creep inadvertently into their work with big data. The biases may be minor or major, episodic or systematic, tangential or material to their findings and recommendations. Whatever their nature, the biases must be understood and corrected as fully as possible.
Here are some of the key sources of bias that may crop up in a data scientist’s work with big data:
- Cognitive bias: This is the tendency to make skewed decisions based on pre-existing cognitive and heuristic factors–such as a misunderstanding of probabilities–rather than on the data and other hard evidence. You might say that the educated intuition that drives data science is rife with cognitive bias, but that’s not always a bad thing.
- Selection bias: This is the tendency to skew your choice of data sources to those that may be most available, convenient, and cost-effective for your purposes, as opposed to being necessarily the most valid and relevant for your study. Clearly, data scientists do not have unlimited budgets, may operate under tight deadlines, and don’t use data for which they lack authorization. These constraints may introduce an unconscious bias in the big-data collections they are able to assemble.
- Sampling bias: This is the tendency to skew the sampling of data sets toward subgroups of the population most relevant to the initial scope of a data-science project, thereby making it unlikely that you will uncover any meaningful correlations that may apply to other segments. Another source of sampling bias is “data dredging,” in which the data scientist uses regression techniques that may find correlations in samples but that may not be statistically significant in the wider population. Consequently, you’re likely to spuriously confirm your initial model for the segments that happen to make the sampling cut.
- Modeling bias: Beyond the biases just discussed, this is the tendency to skew data-science models by starting with a biased set of project assumptions that drive selection of the wrong variables, the wrong data, the wrong algorithms, and the wrong metrics of fitness. In addition, overfitting of models to past data without regard for predictive lift is a common bias. Likewise, failure to score and iterate models in a timely fashion with fresh observational data also introduces model decay, hence bias.
- Funding bias: This may be the most silent but pernicious bias in data-scientific studies of all sorts. It’s the unconscious tendency to skew all modeling assumptions, interpretations, data, and applications to favor the interests of the party–employer, customer, sponsor, etc.–that employs or otherwise financially supports the data-science initiative. Funding bias makes it highly unlikely that data scientists will uncover disruptive insights that will “break the rice bowl” in which they make their living.
Q5. How do you measure “success” when analysing data?
James Kobielus: You measure success in your ability to distill useful insights in a timely fashion from the data at your disposal.
Q6. What skills are required to be an effective Data Scientist?
James Kobielus: Data science’s learning curve is formidable. To a great degree, you will need a degree, or something substantially like it, to prove you’re committed to this career. You will need to submit yourself to a structured curriculum to certify you’ve spent the time, money and midnight oil necessary for mastering this demanding discipline.
Sure, there are run-of-the-mill degrees in data-science-related fields, and then there are uppercase, boldface, bragging-rights “DEGREES.” To some extent, it matters whether you get that old data-science sheepskin from a traditional university vs. an online school vs. a vendor-sponsored learning program. And it matters whether you only logged a year in the classroom vs. sacrificed a considerable portion of your life reaching for the golden ring of a Ph.D. And it certainly matters whether you simply skimmed the surface of old-school data science vs. pursued a deep specialization in a leading-edge advanced analytic discipline.
But what matters most to modern business isn’t that every data scientist has a big honking doctorate. What matters most is that a substantial body of personnel has a common grounding in core curriculum of skills, tools and approaches. Ideally, you want to build a team where diverse specialists with a shared foundation can collaborate productively.
Big data initiatives thrive if all data scientists have been trained and certified on a curriculum with the following foundation:
- Paradigms and practices: Every data scientist should acquire a grounding in core concepts of data science, analytics and data management. They should gain a common understanding of the data science lifecycle, as well as the typical roles and responsibilities of data scientists in every phase. They should be instructed on the various role(s) of data scientists and how they work in teams and in conjunction with business domain experts and stakeholders. And they learn a standard approach for establishing, managing and operationalizing data science projects in the business.
- Algorithms and modeling: Every data scientist should obtain a core understanding of linear algebra, basic statistics, linear and logistic regression, data mining, predictive modeling, cluster analysis, association rules, market basket analysis, decision trees, time-series analysis, forecasting, machine learning, Bayesian and Monte Carlo Statistics, matrix operations, sampling, text analytics, summarization, classification, primary components analysis, experimental design, unsupervised learning constrained optimization.
- Tools and platforms: Every data scientist should master a core group of modeling, development and visualization tools used on your data science projects, as well as the platforms used for storage, execution, integration and governance of big data in your organization. Depending on your environment, and the extent to which data scientists work with both structured and unstructured data, this may involve some combination of data warehousing, Hadoop, stream computing, NoSQL and other platforms. It will probably also entail providing instruction in MapReduce, R and other new open-source development languages, in addition to SPSS, SAS and any other established tools.
- Applications and outcomes: Every data scientist should learn the chief business applications of data science in your organization, as well as in how to work best with subject-domain experts. In many companies, data science focuses on marketing, customer service, next best offer, and other customer-centric applications. Often, these applications require that data scientists understand how to leverage customer data acquired from structured survey tools, sentiment analysis software, social media monitoring tools and other sources. It also essential that every data scientist gain an understanding of the key business outcomes–such as maximizing customer lifetime value–that should focus their modeling initiatives.
Classroom instruction is important, but a curriculum that is 100 percent devoted to reading books, taking tests and sitting through lectures is insufficient. Hands-on laboratory work is paramount for a truly well-rounded data scientist. Make sure that your data scientists acquire certifications and degrees that reflect them actually developing statistical models that use real data and address substantive business issues.
A business-oriented data-science curriculum should produce expert developers of statistical and predictive models. It should not degenerate into a program that produces analytics geeks with heads stuffed with theory but whose diplomas are only fit for hanging on the wall.
Q7. Hadoop vs. Spark: what are the pros and cons?
James Kobielus: Big data analytics infrastructures are growing more hybridized than ever. Every new technology—such as Hadoop, in-memory databases, and graph databases—finds its specific niche in terms of use cases, deployment modes, and applications for which it is best suited.
Even as Apache Spark pushes more deeply into big-data environments, it won’t substantially change this trend. Yes, of course Spark is on the fast track to ubiquity in big-data analytics. This is especially true for the next generation of machine-learning applications that feed on growing in-memory pools and require low-latency distributed computations for streaming and graph analytics. But those use cases aren’t the sum total of big-data analytics and never will be.
As we all grow more infatuated with Spark, it’s important to continually remind ourselves of what it’s not suitable for. If, for example, one considers all the critical data management, integration, and preparation tasks that must be performed prior to modeling in Spark, it’s clear that these will not be executed in any of the Spark engines (Spark SQL, Spark Streaming, GraphX). Instead, they’ll be carried out in the data platforms and elastic clusters (HDFS, Cassandra, HBase, Mesos, cloud services, etc.) upon which those engines run. Likewise, you’d be hardpressed to find anyone who’s seriously considering Spark in isolation for data warehousing, data governance, master data management, or operational business intelligence.
Above all else, Spark is the new power tool for data scientists who are pushing boundaries in the emerging era of in-memory big data analytics in low-latency scenarios of all types. Spark is proving its value as a development tool for the new generation of data scientists building the in-memory statistical models upon which it all will depend.
Let’s not fall into the delusion that everything is converging toward Spark, as if it were the ravenous maw that will devour every other big-data analytics tool and platform. Spark is just another approach that’s being fitted to and optimized for specific purposes.
And let’s resist the hype that treats Spark as Hadoop’s “successor.” This implies that Hadoop and other big-data approaches are “legacy,” rather than what they are, which is foundational. For example, no one is seriously considering doing “data lakes,” “data reservoirs,” or “data refineries” on anything but Hadoop or NoSQL.
——————–
James Kobielus is an industry veteran and serves as IBM Big Data Evangelist; Senior Program Director for Product Marketing in Big Data Analytics; and Team Lead, Technical Marketing, IBM Big Data & Analytics Hub. He spearheads thought leadership activities across the IBM Analytics solution portfolio. He has spoken at such leading industry events as IBM Insight, Hadoop Summit, and Strata. He has published several business technology books and is a very popular provider of original commentary on blogs and many social media.
Resources
– Master of Information and Data Science, UC Berkeley School of Information.
– MS in Data Science, NYU Center for Data Science.
– Free data science curriculum, kdnuggets.com
– Master of Science in Data Science – Data Science Institute
–Data Mining and Applications Graduate Certificate, Stanford
–The European Data Science Academy (EDSA) designs curricula for data science training and data science education across the European Union (EU).
-The EDISON project will focus on activities to establish the new profession of ‘Data Scientist’, following the emergence of Data Science technologies (also referred to as Data Intensive or Big Data technologies) which changes the way research is done, how scientists think and how the research data are used and shared. This includes definition of the required skills, competences framework/profile, corresponding Body Of Knowledge and model curriculum. It will develop a sustainability/business model to ensure a sustainable increase of Data Scientists, graduated from universities and trained by other professional education and training institutions in Europe.
EDISON will facilitate the establishment of a Data Science education and training infrastructure at major European universities by promoting experience of ‘champion’ universities involving them into coordinated development and implementation of the model curriculum and creation of cooperative educational and training infrastructure.
Related Posts
Follow us on Twitter: @odbmsorg
##
” A revolution will happen when tools like Siri can truly serve as your personal assistant and you start relying on such an assistant throughout your day. To get there, these systems need more knowledge about your life and preferences, more knowledge about the world, better conversational interfaces and at least basic commonsense reasoning capabilities. We’re still quite far from achieving these goals.”–Alon Halevy
I have interviewed Alon Halevy, CEO at Recruit Institute of Technology.
RVZ
Q1. What is the mission of the Recruit Institute of Technology?
Alon Halevy: Before I describe the mission, I should introduce our parent company Recruit Holdings to those who may not be familiar with it. Recruit (founded in 1960), is a leading “life-style” information services and human resources company in Japan with services in the areas of recruitment, advertising, employment placement, staffing, education, housing and real estate, bridal, travel, dining, beauty, automobiles and others. The company is currently expanding worldwide and operates similar businesses in the U.S., Europe and Asia. In terms of size, Recruit has over 30,000 employees and its revenues are similar to those of Facebook at this point in time.
The mission of R.I.T is threefold. First, being the lab of Recruit Holdings, our goal is to develop technologies that improve the products and services of our subsidiary companies and create value for our customers from the vast collections of data we have. Second, our mission is to advance scientific knowledge by contributing to the research community through publications in top-notch venues. Third, we strive to use technology for social good. This latter goal may be achieved through contributing to open-source software, working on digital artifacts that would be of general use to society, or even working with experts in a particular domain to contribute to a cause.
Q2. Isn`t similar to the mission of the Allen Institute for Artificial Intelligence?
Alon Halevy: The Allen Institute is a non-profit whose admirable goal is to make fundamental contributions to Artificial Intelligence. While R.I.T strives to make fundamental contributions to A.I and related areas such as data management, we plan to work closely with our subsidiary companies and to impact the world through their products.
Q3. Driverless cars, digital Personal Assistants (e.g. Siri), Big Data, the Internet of Things, Robots: Are we on the brink of the next stage of the computer revolution?
Alon Halevy: I think we are seeing many applications in which AI and data (big or small) are starting to make a real difference and affecting people’s lives. We will see much more of it in the next few years as we refine our techniques. A revolution will happen when tools like Siri can truly serve as your personal assistant and you start relying on such an assistant throughout your day. To get there, these systems need more knowledge about your life and preferences, more knowledge about the world, better conversational interfaces and at least basic commonsense reasoning capabilities. We’re still quite far from achieving these goals.
Q4. You were for more than 10 years senior staff research scientist at Google, leading the Structured Data Group in Google Research. Was it difficult to leave Google?
Alon Halevy: It was extremely difficult leaving Google! I struggled with the decision for quite a while, and waving goodbye to my amazing team on my last day was emotionally heart wrenching. Google is an amazing company and I learned so much from my colleagues there. Fortunately, I’m very excited about my new colleagues and the entrepreneurial spirit of Recruit.
One of my goals at R.I.T is to build a lab with the same culture as that of Google and Google Research. So in a sense, I’m hoping to take Google with me. Some of my experiences from a decade at Google that are relevant to building a successful research lab are described in a blog post I contributed to the SIGMOD blog in September, 2015.
Q5. What is your vision for the next three years for the Recruit Institute of Technology?
Alon Halevy: I want to build a vibrant lab with world-class researchers and engineers. I would like the lab to become a world leader in the broad area of making data usable, which includes data discovery, cleaning, integration, visualization and analysis.
In addition, I would like the lab to build collaborations with disciplines outside of Computer Science where computing techniques can make an even broader impact on society.
Q6. What are the most important research topics you intend to work on?
Alon Halevy: One of the roadblocks to applying AI and analysis techniques more widely within enterprises is data preparation.
Before you can analyze data or apply AI techniques to it, you need to be able to discover which datasets exist in the enterprise, understand the semantics of a dataset and its underlying assumptions, and to combine disparate datasets as needed. We plan to work on the full spectrum of these challenges with the goal of enabling many more people in the enterprise to explore their data.
Recruit being a lifestyle company, another fundamental question we plan to investigate is whether technology can help people make better life decisions. In particular, can technology help you take into consideration many factors in your life as you make decisions and steer you towards decisions that will make you happier over time. Clearly, we’ll need more than computer scientists to even ask the right questions here.
Q7. If we delegate decisions to machines, who will be responsible for the consequences? What are the ethical responsibilities of designers of intelligent systems?
Alon Halevy: You got an excellent answer from Oren Etzioni to this question in a recent interview. I agree with him fully and could not say it any better than he did.
Qx Anything you wish to add?
Alon Halevy: Yes. We’re hiring! If you’re a researcher or strong engineer who wants to make real impact on products and services in the fascinating area of lifestyle events and decision making, please consider R.I.T!
———-
Alon Halevy is the Executive Director of the Recruit Institute of Technology. From 2005 to 2015 he headed the Structured Data Management Research group at Google. Prior to that, he was a professor of Computer Science at the University of Washington in Seattle, where he founded the Database Group. In 1999, Dr. Halevy co-founded Nimble Technology, one of the first companies in the Enterprise Information Integration space, and in 2004, Dr. Halevy founded Transformic, a company that created search engines for the deep web, and was acquired by Google.
Dr. Halevy is a Fellow of the Association for Computing Machinery, received the Presidential Early Career Award for Scientists and Engineers (PECASE) in 2000, and was a Sloan Fellow (1999-2000). Halevy is the author of the book “The Infinite Emotions of Coffee”, published in 2011, and serves on the board of the Alliance of Coffee Excellence.
He is also a co-author of the book “Principles of Data Integration”, published in 2012.
Dr. Halevy received his Ph.D in Computer Science from Stanford University in 1993 and his Bachelors from the Hebrew University in Jerusalem.
Resources
– Civility in the Age of Artificial Intelligence, by STEVE LOHR, technology reporter for The New York Times, ODBMS.org
–The threat from AI is real, but everyone has it wrong, by Robert Munro, CEO Idibon, ODBMS.org
Related Posts
– On Artificial Intelligence and Society. Interview with Oren Etzioni, ODBMS Industry Watch.
– On Big Data and Society. Interview with Viktor Mayer-Schönberger, ODBMS Industry Watch.
Follow us on Twitter: @odbmsorg
##
“Frankly, manufacturers are terrified to flood their data centers with these unprecedented volumes of sensor and network data.”– Colin Mahony
I have interviewed Colin Mahony, SVP & General Manager, HPE Big Data Platform. Topics of the interview are: The challenges of the Internet of Things, the opportunities for Data Analytics, the positioning of HPE Vertica and HPE Cloud Strategy.
RVZ
Q1. Gartner says 6.4 billion connected “things” will be in use in 2016, up 30 percent from 2015. How do you see the global Internet of Things (IoT) market developing in the next years?
Colin Mahony: As manufacturers connect more of their “things,” they have an increased need for analytics to derive insight from massive volumes of sensor or machine data. I see these manufacturers, particularly manufacturers of commodity equipment, with a need to provide more value-added services based on their ability to provide higher levels of service and overall customer satisfaction. Data analytics platforms are key to making that happen. Also, we could see entirely new analytical applications emerge, driven by what consumers want to know about their devices and combine that data with, say, their exercise regimens, health vitals, social activities, and even driving behavior, for full personal insight.
Ultimately, the Internet of Things will drive a need for the Analyzer of Things, and that is our mission.
Q2. What Challenges and Opportunities bring the Internet of Things (IoT)?
Colin Mahony: Frankly, manufacturers are terrified to flood their data centers with these unprecedented volumes of sensor and network data. The reason? Traditional data warehouses were designed well before the Internet of Things, or, at least before OT (operational technology) like medical devices, industrial equipment, cars, and more were connected to the Internet. So, having an analytical platform to provide the scale and performance required to handle these volumes is important, but customers are taking more of a two- or three-tier approach that involves some sort of analytical processing at the edge before data is sent to an analytical data store. Apache Kafka is also becoming an important tier in this architecture, serving as a message bus, to collect and push that data from the edge in streams to the appropriate database, CRM system, or analytical platform for, as an example, correlation of fault data over months or even years to predict and prevent part failure and optimize inventory levels.
Q3. Big Data: In your opinion, what are the current main demands/needs in the market?
Colin Mahony: All organizations want – and need – to become data-driven organizations. I mean, who wants to make such critical decisions based on half answers and anecdotal data? That said, traditional companies with data stores and systems going back 30-40 years don’t have the same level playing field as the next market disruptor that just received their series B funding and only knows that analytics is the life blood of their business and all their critical decisions.
The good news is that whether you are a 100-year old insurance company or the next Uber or Facebook, you can become a data-driven organization by taking an open platform approach that uses the best tool for the job and can incorporate emerging technologies like Kafka and Spark without having to bolt on or buy all of that technology from a single vendor and get locked in. Understanding the difference between an open platform with a rich ecosystem and open source software as one very important part of that ecosystem has been a differentiator for our customers.
Beyond technology, we have customers that establish analytical centers of excellence that actually work with the data consumers – often business analysts – that run ad-hoc queries using their preferred data visualization tool to get the insight need for their business unit or department. If the data analysts struggle, then this center of excellence, which happens to report up through IT, collaborates with them to understand and help them get to the analytical insight – rather than simply halting the queries with no guidance on how to improve.
Q4. How do you embed analytics and why is it useful?
Colin Mahony: OEM software vendors, particularly, see the value of embedding analytics in their commercial software products or software as a service (SaaS) offerings. They profit by creating analytic data management features or entirely new applications that put customers on a faster path to better, data-driven decision making. Offering such analytics capabilities enables them to not only keep a larger share of their customer’s budget, but at the same time greatly improve customer satisfaction. To offer such capabilities, many embedded software providers are attempting unorthodox fixes with row-oriented OLTP databases, document stores, and Hadoop variations that were never designed for heavy analytic workloads at the volume, velocity, and variety of today’s enterprise. Alternatively, some companies are attempting to build their own big data management systems. But such custom database solutions can take thousands of hours of research and development, require specialized support and training, and may not be as adaptable to continuous enhancement as a pure-play analytics platform. Both approaches are costly and often outside the core competency of businesses that are looking to bring solutions to market quickly.
Because it’s specifically designed for analytic workloads, HPE Vertica is quite different from other commercial alternatives. Vertica differs from OLTP DBMS and proprietary appliances (which typically embed row-store DBMSs) by grouping data together on disk by column rather than by row (that is, so that the next piece of data read off disk is the next attribute in a column, not the next attribute in a row). This enables Vertica to read only the columns referenced by the query, instead of scanning the whole table as row-oriented databases must do. This speeds up query processing dramatically by reducing disk I/O.
You’ll find Vertica as the core analytical engine behind some popular products, including Lancope, Empirix, Good Data, and others as well as many HPE offerings like HPE Operations Analytics, HPE Application Defender, and HPE App Pulse Mobile, and more.
Q5. How do you make a decision when it is more appropriate to “consume and deploy” Big Data on premise, in the cloud, on demand and on Hadoop?
Colin Mahony: The best part is that you don’t need to choose with HPE. Unlike most emerging data warehouses as a service where your data is trapped in their databases when your priorities or IT policies change, HPE offers the most complete range of deployment and consumption models. If you want to spin up your analytical initiative on the cloud for a proof-of-concept or during the holiday shopping season for e-retailers, you can do that easily with HPE Vertica OnDemand.
If your organization finds that due to security or confidentiality or privacy concerns you need to bring your analytical initiative back in house, then you can use HPE Vertica Enterprise on-premises without losing any customizations or disruption to your business. Have petabyte volumes of largely unstructured data where the value is unknown? Use HPE Vertica for SQL on Hadoop, deployed natively on your Hadoop cluster, regardless of the distribution you have chosen. Each consumption model, available in the cloud, on-premise, on-demand, or using reference architectures for HPE servers, is available to you with that same trusted underlying core.
Q6. What are the new class of infrastructures called “composable”? Are they relevant for Big Data?
Colin Mahony: HPE believes that a new architecture is needed for Big Data – one that is designed to power innovation and value creation for the new breed of applications while running traditional workloads more efficiently.
We call this new architectural approach Composable Infrastructure. HPE has a well-established track record of infrastructure innovation and success. HPE Converged Infrastructure, software-defined management, and hyper-converged systems have consistently proven to reduce costs and increase operational efficiency by eliminating silos and freeing available compute, storage, and networking resources. Building on our converged infrastructure knowledge and experience, we have designed a new architecture that can meet the growing demands for a faster, more open, and continuous infrastructure.
Q7. What is HPE Cloud Strategy?
Colin Mahony: Hybrid cloud adoption is continuing to grow at a rapid rate and a majority of our customers recognize that they simply can’t achieve the full measure of their business goals by consuming only one kind of cloud.
HPE Helion not only offers private cloud deployments and managed private cloud services, but we have created the HPE Helion Network, a global ecosystem of service providers, ISVs, and VARs dedicated to delivering open standards-based hybrid cloud services to enterprise customers. Through our ecosystem, our customers gain access to an expanded set of cloud services and improve their abilities to meet country-specific data regulations.
In addition to the private cloud offerings, we have a strategic and close alliance with Microsoft Azure, which enables many of our offerings, including Haven OnDemand, in the public cloud. We also work closely with Amazon because our strategy is not to limit our customers, but to ensure that they have the choices they need and the services and support they can depend upon.
Q8. What are the advantages of an offering like Vertica in this space?
Colin Mahony: More and more companies are exploring the possibility of moving their data analytics operations to the cloud. We offer HPE Vertica OnDemand, our data warehouse as a service, for organizations that need high-performance enterprise class data analytics for all of their data to make better business decisions now. Built by design to drastically improve query performance over traditional relational database systems, HPE Vertica OnDemand is engineered from the same technology that powers the HPE Vertica Analytics Platform. For organizations that want to select Amazon hardware and still maintain the control over the installation, configuration, and overall maintenance of Vertica for ultimate performance and control, we offer Vertica AMI (Amazon Machine Image). The Vertica AMI is a bring-your-own-license model that is ideal for organizations that want the same experience as on-premise installations, only without procuring and setting up hardware. Regardless of which deployment model to choose, we have you covered for “on demand” or “enterprise cloud” options.
Q9. What is HPE Vertica Community Edition?
Colin Mahony: We have had tens of thousands of downloads of the HPE Vertica Community Edition, a freemium edition of HPE Vertica with all of the core features and functionality that you experience with our core enterprise offering. It’s completely free for up to 1 TB of data storage across three nodes. Companies of all sizes prefer the Community Edition to download, install, set-up, and configure Vertica very quickly on x86 hardware or use our Amazon Machine Image (AMI) for a bring-your-own-license approach to the cloud.
Q10. Can you tell us how Kiva.org, a non-profit organization, uses on-demand cloud analytics to leverage the internet and a worldwide network of microfinance institutions to help fight poverty?
Colin Mahony: HPE is a major supporter of Kiva.org, a non-profit organization with a mission to connect people through lending to alleviate poverty. Kiva.org uses the internet and a worldwide network of microfinance institutions to enable individuals lend as little as $25 to help create opportunity around the world. When the opportunity arose to help support Kiva.org with an analytical platform to further the cause, we jumped at the opportunity. Kiva.org relies on Vertica OnDemand to reduce capital costs, leverage the SaaS delivery model to adapt more quickly to changing business requirements, and work with over a million lenders, hundreds of field partners and volunteers, across the world. To see a recorded Webinar with HPE and Kiva.org, see here.
Qx Anything else you wish to add?
Colin Mahony: We appreciate the opportunity to share the features and benefits of HPE Vertica as well as the bright market outlook for data-driven organizations. However, I always recommend that any organization that is struggling with how to get started with their analytics initiative to speak and meet with peers to learn best practices and avoid potential pitfalls. The best way to do that, in my opinion, is to visit with the more than 1,000 Big Data experts in Boston from August 29 – September 1st at the HPE Big Data Conference. Click here to learn more and join us for 40+ technical deep-dive sessions.
————-
Colin Mahony, SVP & General Manager, HPE Big Data Platform
Colin Mahony leads the Hewlett Packard Enterprise Big Data Platform business group, which is responsible for the industry leading Vertica Advanced Analytics portfolio, the IDOL Enterprise software that provides context and analysis of unstructured data, and Haven OnDemand, a platform for developers to leverage APIs and on demand services for their applications.
In 2011, Colin joined Hewlett Packard as part of the highly successful acquisition of Vertica, and took on the responsibility of VP and General Manager for HP Vertica, where he guided the business to remarkable annual growth and recognized industry leadership. Colin brings a unique combination of technical knowledge, market intelligence, customer relationships, and strategic partnerships to one of the fastest growing and most exciting segments of HP Software.
Prior to Vertica, Colin was a Vice President at Bessemer Venture Partners focused on investments primarily in enterprise software, telecommunications, and digital media. He established a great network and reputation for assisting in the creation and ongoing operations of companies through his knowledge of technology, markets and general management in both small startups and larger companies. Prior to Bessemer, Colin worked at Lazard Technology Partners in a similar investor capacity.
Prior to his venture capital experience, Colin was a Senior Analyst at the Yankee Group serving as an industry analyst and consultant covering databases, BI, middleware, application servers and ERP systems. Colin helped build the ERP and Internet Computing Strategies practice at Yankee in the late nineties.
Colin earned an M.B.A. from Harvard Business School and a bachelor’s degrees in Economics with a minor in Computer Science from Georgetown University. He is an active volunteer with Big Brothers Big Sisters of Massachusetts Bay and the Joey Fund for Cystic Fibrosis.
Resources
–What’s in store for Big Data analytics in 2016, Steve Sarsfield, Hewlett Packard Enterprise. ODBMS.org, 3 FEB, 2016
–What’s New in Vertica 7.2?: Apache Kafka Integration!, HPE, last edited February 2, 2016
–Gartner Says 6.4 Billion Connected “Things” Will Be in Use in 2016, Up 30 Percent From 2015, Press release, November 10, 2015
–The Benefits of HP Vertica for SQL on Hadoop, HPE, July 13, 2015
–Uplevel Big Data Analytics with Graph in Vertica – Part 5: Putting graph to work for your business , Walter Maguire, Chief Field Technologist, HP Big Data Group, ODBMS.org, 2 Nov, 2015
–HP Distributed R ,ODBMS.org, 19 FEB, 2015.
–Understanding ROS and WOS: A Hybrid Data Storage Model, HPE, October 7, 2015
Related Posts
–On Big Data Analytics. Interview with Shilpa Lawande, Source: ODBMS Industry Watch, Published on December 10, 2015
–On HP Distributed R. Interview with Walter Maguire and Indrajit Roy, Source: ODBMS Industry Watch, Published on April 9, 2015
Follow us on Twitter: @odbmsorg
##
“Leading enterprises have a firm grasp of the technology edge that’s relevant to them. Better data analysis and disambiguation through semantics is central to how they gain competitive advantage today.”–Alan Morrison.
I have interviewed Alan Morrison, senior research fellow at PwC, Center for Technology and Innovation.
Main topic of the interview is how the Big Data market is evolving.
RVZ
Q1. How do you see the Big Data market evolving?
Alan Morrison: We should note first of all how true Big Data and analytics methods emerged and what has been disruptive. Over the course of a decade, web companies have donated IP and millions of lines of code that serves as the foundation for what’s being built on top. In the process, they’ve built an open source culture that is currently driving most big data-related innovation. As you mentioned to me last year, Roberto, a lot of database innovation was the result of people outside the world of databases changing what they thought needed to be fixed, people who really weren’t versed in the database technologies to begin with.
Enterprises and the database and analytics systems vendors who serve them have to constantly adjust to the innovation that’s being pushed into the open source big data analytics pipeline. Open source machine learning is becoming the icing on top of that layer cake.
Q2. In your opinion what are the challenges of using Big Data technologies in the enterprise?
Alan Morrison: Traditional enterprise developers were thrown for a loop back in the late 2000s when it comes to open source software, and they’re still adjusting. The severity of the problem differs depending on the age of the enterprise. In our 2012 issue of the Forecast on DevOps, we made clear distinctions between three age classes of companies: legacy mainstream enterprises, pre-cloud enterprises and cloud natives. Legacy enterprises could have systems that are 50 years old or more still in place and have simply added to those. Pre-cloud enterprises are fighting with legacy that’s up to 20 years old. Cloud natives don’t have to fight legacy and can start from scratch with current tech.
DevOps (dev + ops) is an evolution of agile development that focuses on closer collaboration between developers and operations personnel. It’s a successor to agile development, a methodology that enables multiple daily updates to operational codebases and feedback-response loop tuning by making small code changes and see how those change user experience and behaviour. The linked article makes a distinction between legacy, pre-cloud and cloud native enterprises in terms of their inherent level of agility:
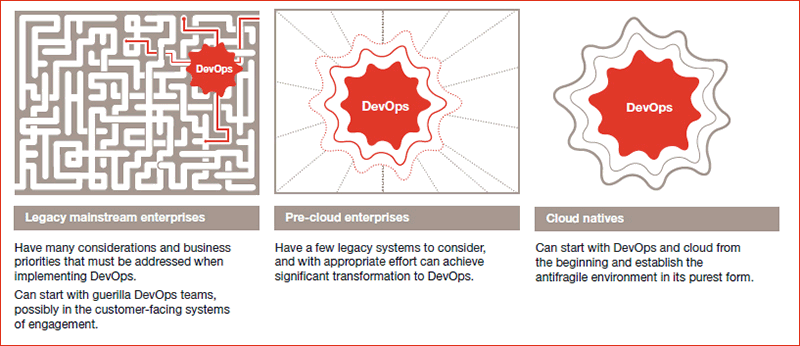
Most enterprises are in the legacy mainstream group, and the technology adoption challenges they face are the same regardless of the technology. To build feedback-response loops for a data-driven enterprise in a legacy environment is more complicated in older enterprises. But you can create guerilla teams to kickstart the innovation process.
Q3. Is the Hadoop ecosystem now ready for enterprise deployment at large scale?
Alan Morrison: Hadoop is ten years old at this point, and Yahoo, a very large mature enterprise, has been running Hadoop on 10,000 nodes for years now. Back in 2010, we profiled a legacy mainstream media company who was doing logfile analysis from all of its numerous web properties on a Hadoop cluster quite effectively. Hadoop is to the point where people in their dens and garages are putting it on Raspberry Pi systems. Lots of companies are storing data in or staging it from HDFS. HDFS is a given. MapReduce, on the other hand, has given way to Spark.
HDFS preserves files in their original format immutably, and that’s important. That innovation was crucial to data-driven application development a decade ago. But Hadoop isn’t the end state for distributed storage, and NoSQL databases aren’t either. It’s best to keep in mind that alternatives to Hadoop and its ecosystem are emerging.
I find it fascinating what folks like LinkedIn and Metamarkets are doing data architecture wise with the Kappa architecture–essentially a stream processing architecture that also works for batch analytics, a system where operational and analytical data are one and the same. That’s appropriate for fully online, all-digital businesses. You can use HDFS, S3, GlusterFS or some other file system along with a database such as Druid. On the transactional side of things, the nascent IPFS (the Interplanetary File System) anticipates both peer-to-peer and the use of blockchains in environments that are more and more distributed. Here’s a diagram we published last year that describes this evolution to date:
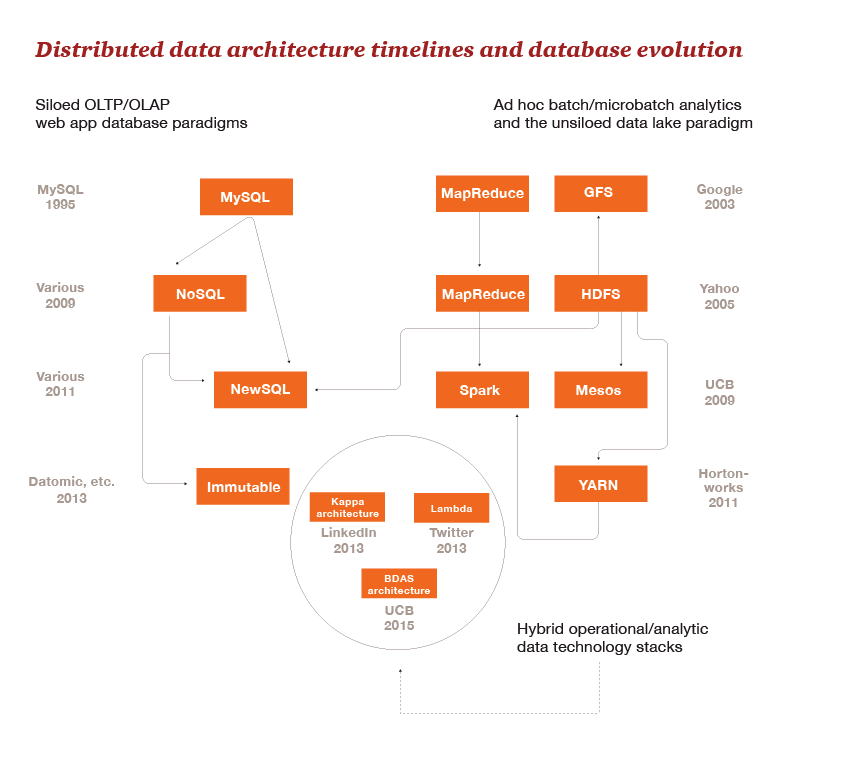
From PWC Technology Forecast 2015
People shouldn’t be focused on Hadoop, but what Hadoop has cleared a path for that comes next.
Q4. What are in your opinion the most innovative Big Data technologies?
Alan Morrison: The rise of immutable data stores (HDFS, Datomic, Couchbase and other comparable databases, as well as blockchains) was significant because it was an acknowledgement that data history and permanence matters, the technology is mature enough and the cost is low enough to eliminate the need to overwrite. These data stores also established that eliminating overwrites also eliminates a cause of contention. We’re moving toward native cloud and eventually the P2P fog (localized, more truly distributed computing) that will extend the footprint of the cloud for the Internet of things.
Unsupervised machine learning has made significant strides in the past year or two, and it has become possible to extract facts from unstructured data, building on the success of entity and relationship extraction. What this advance implies is the ability to put humans in feedback loops with machines, where they let machines discover the data models and facts and then tune or verify those data models and facts.
In other words, large enterprises now have the capability to build their own industry- and organization-specific knowledge graphs and begin to develop cognitive or intelligent apps on top those knowledge graphs, along the lines of what Cirrus Shakeri of Inventurist envisions.
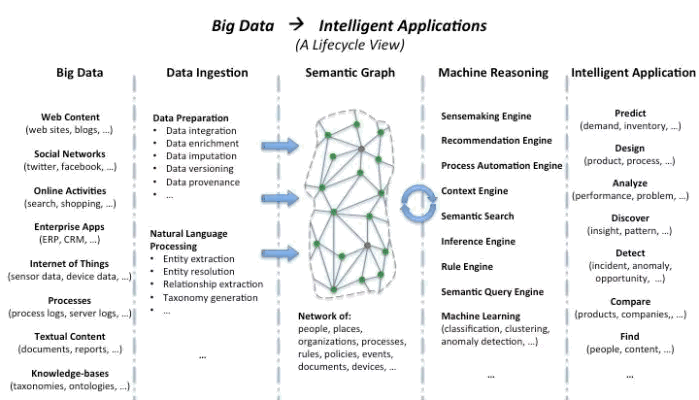
From Cirrus Shakeri, “From Big Data to Intelligent Applications,” post, January 2015
At the core of computable semantic graphs (Shakeri’s term for knowledge graphs or computable knowledge bases) is logically consistent semantic metadata. A machine-assisted process can help with entity and relationship extraction and then also ontology generation.
Computability = machine readability. Semantic metadata–the kind of metadata cognitive computing apps use–can be generated with the help of a well-designed and updated ontology. More and more, these ontologies are uncovered in text rather than hand built, but again, there’s no substitute for humans in the loop. Think of the process of cognitive app development as a continual feedback-response loop process. The use of agents can facilitate the construction of these feedback loops.
Q5. In a recent note Carl Olofson, Research Vice President, Data Management Software Research, IDC, predicted the RIP of “Big Data” as a concept. What is your view on this?
Alan Morrison: I agree the term is nebulous and can be misleading, and we’ve had our fill of it. But that doesn’t mean it won’t continue to be used. Here’s how we defined it back in 2009:
Big Data is not a precise term; rather, it is a characterization of the never-ending accumulation of all kinds of data, most of it unstructured. It describes data sets that are growing exponentially and that are too large, too raw, or too unstructured for analysis using relational database techniques. Whether terabytes or petabytes, the precise amount is less the issue than where the data ends up and how it is used. (See https://www.pwc.com/us/en/technology-forecast/assets/pwc-tech-forecast-issue3-2010.pdf, pg. 6.)
For that issue of the Forecast, we focused on how Hadoop was being piloted in enterprises and the ecosystem that was developing around it. Hadoop was the primary disruptive technology, as well as NoSQL databases. It helps to consider the data challenge of the 2000s and how relational databases and enterprise data warehousing techniques were falling short at that point. Hadoop has reduced the cost of analyzing data by an order of magnitude and allows processing of very large unstructured datasets. NoSQL has made it possible to move away from rigid data models and standard ETL.
“Big Data” can continue to be shorthand for petabytes of unruly, less structured data. But why not talk about the system instead of just the data? I like the term that George Gilbert of Wikibon latched on to last year. I don’t know if he originated it, but he refers to the System of Intelligence. That term gets us beyond the legacy, pre-web “business intelligence” term, more into actionable knowledge outputs that go beyond traditional reporting and into the realm of big data, machine learning and more distributed systems. The Hadoop ecosystem, other distributed file systems, NoSQL databases and the new analytics capabilities that rely on them are really at the heart of a System of Intelligence.
Q6. How many enterprise IT systems do you think we will need to interoperate in the future?
Alan Morrison: I like Geoffrey Moore‘s observations about a System of Engagement that emerged after the System of Record, and just last year George Gilbert was adding to that taxonomy with a System of Intelligence. But you could add further to that with a System of Collection that we still need to build. Just to be consistent, the System of Collection articulates how the Internet of Things at scale would function on the input side. The System of Engagement would allow distribution of the outputs. For the outputs of the System of Collection to be useful, that system will need to interoperate in various ways with the other systems.
To summarize, there will actually be four enterprise IT systems that will need to interoperate, ultimately. Three of these exist, and one still needs to be created.
- System of Collection: The Internet of Things ( (The Fog–yet to be created)–see Maher Abdelshkour, IoT, from Cloud to Fog Computing
- System of Intelligence: big data, analytics, machine learning (The Cloud) –see George Gilbert on Systems of Intelligence: The Next Generation of Enterprise Applications built on Big Data
- System of Engagement: social, mobile (The Cloud) See Geoffrey Moore,Systems of Engagement and the Future of Enterprise IT: A Sea Change in Enterprise IT
- System of Record: ERP, CRM, SCM…. (The Core) Also described in Moore’s article above
The fuller picture will only emerge when this interoperation becomes possible.
Q7. What are the requirements, heritage and legacy of such systems?
Alan Morrison: The System of Record (RDBMSes) still relies on databases and tech with their roots in the pre-web era. I’m not saying these systems haven’t been substantially evolved and refined, but they do still reflect a centralized, pre-web mentality. Bitcoin and Blockchain make it clear that the future of Systems of Record won’t always be centralized. In fact, microtransaction flows in the Internet of Things at scale will depend on the decentralized approaches, algorithmic transaction validation, and immutable audit trail creation which blockchain inspires.
The Web is only an interim step in the distributed system evolution. P2P systems will eventually complemnt the web, but they’ll take a long time to kick in fully–well into the next decade. There’s always the S-curve of adoption that starts flat for years. P2P has ten years of an installed base of cloud tech, twenty years of web tech and fifty years plus of centralized computing to fight with. The bitcoin blockchain seems to have kicked P2P in gear finally, but progress will be slow through 2020.
The System of Engagement (requiring Web DBs) primarily relies on Web technnology (MySQL and NoSQL) in conjunction with traditional CRM and other customer-related structured databases.
The System of Intelligence (requiring Web file systems and less structured DBs) primarily relies on NoSQL, Hadoop, the Hadoop ecosystem and its successors, but is built around a core DW/DM RDBMS analytics environment with ETLed structured data from the System of Record and System of Engagement. The System of Intelligence will have to scale and evolve to accommodate input from the System of Collection.
The System of Collection (requiring distributed file systems and DBs) will rely on distributed file system successors to Hadoop and HTTP such as IPFS and the more distributed successors to MySQL+ NoSQL. Over the very long term, a peer-to-peer architecture will emerge that will become necessary to extend the footprint of the internet of things and allow it to scale.
Q8. Do you already have the piece parts to begin to build out a 2020+ intersystem vision now?
Alan Morrison: Contextual, ubiquitous computing is the vision of the 2020s, but to get to that, we need an intersystem approach. Without interoperation of the four systems I’ve alluded to, enterprises won’t be able to deliver the context required for competitive advantage. Without sufficient entity and relationship disambiguation via machine learning in machine/human feedback loops, enterprises won’t be able to deliver the relevance for competitive advantage.
We do have the piece parts to begin to build out an intersystem vision now. For example, interoperation is a primary stumbling block that can be overcome now. Middleware has been overly complex and inadequate to the current-day task, but middleware platforms such as EnterpriseWeb are emerging that can reach out as an integration fabric for all systems, up and down the stack. Here’s how the integration fabric becomes an essential enabler for the intersystem approach:
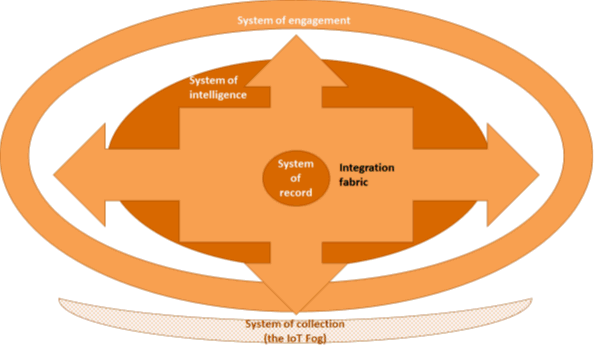
PwC, 2015
A lot of what EnterpriseWeb (full disclosure: a JBR partner of PwC) does hinges on the creation and use of agents and semantic metadata that enable the data/logic virtualization. That’s what makes the desiloing possible. One of the things about the EnterpriseWeb platform is that it’s a full stack virtual integration and application platform, using methods that have data layer granularity, but process layer impact. Enterprise architects can tune their models and update operational processes at the same time. The result: every change is model-driven and near real-time. Stacks can all be simplified down to uniform, virtualized composable entities using enabling technologies that work at the data layer. Here’s how they work:
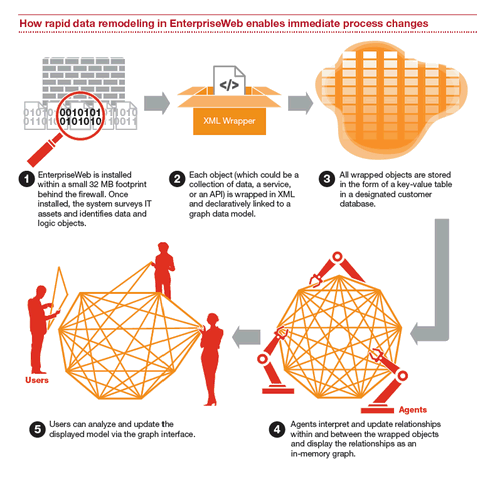
PwC, 2015
So basically you can do process refinement across these systems, and intersystem analytics views thus also become possible.
Qx anything else you wish to add?
Alan Morrison: We always quote science fiction writer William Gibson, who said,
“The future is already here — it’s just not very evenly distributed.”
Enterprises would do best to remind themselves what’s possible now and start working with it. You’ve got to grab onto that technology edge and let it pull you forward. If you don’t understand what’s possible, most relevant to your future business success and how to use it, you’ll never make progress and you’ll always be reacting to crises. Leading enterprises have a firm grasp of the technology edge that’s relevant to them. Better data analysis and disambiguation through semantics is central to how they gain competitive advantage today.
We do a ton of research to get to the big picture and find the real edge, where tech could actually have a major business impact. And we try to think about what the business impact will be, rather than just thinking about the tech. Most folks who are down in the trenches are dismissive of the big picture, but the fact is they aren’t seeing enough of the horizon to make an informed judgement. They are trying to use tools they’re familiar with to address problems the tools weren’t designed for. Alongside them should be some informed contrarians and innovators to provide balance and get to a happy medium.
That’s how you counter groupthink in an enterprise. Executives need to clear a path for innovation and foster a healthy, forward-looking, positive and tolerant mentality. If the workforce is cynical, that’s an indication that they lack a sense of purpose or are facing systemic or organizational problems they can’t overcome on their own.
—————–
Alan Morrison (@AlanMorrison) is a senior research fellow at PwC, a longtime technology trends analyst and an issue editor of the firm’s Technology Forecast
Resources
Data-driven payments. How financial institutions can win in a networked economy, BY, Mark Flamme, Partner; Kevin Grieve, Partner; Mike Horvath, Principal Strategy&. FEBRUARY 4, 2016, ODBMS.org
The rise of immutable data stores, By Alan Morrison, Senior Manager, PwC Center for technology and innovation (CTI), OCTOBER 9, 2015, ODBMS.org
The enterprise data lake: Better integration and deeper analytics, By Brian Stein and Alan Morrison, PwC, AUGUST 20, 2014 ODBMS.org
Related Posts
On the Industrial Internet of Things. Interview with Leon Guzenda , ODBMS Industry Watch, January 28, 2016
On Big Data and Society. Interview with Viktor Mayer-Schönberger , ODBMS Industry Watch, January 8, 2016
On Big Data Analytics. Interview with Shilpa Lawande , ODBMS Industry Watch, December 10, 2015
On Dark Data. Interview with Gideon Goldin , ODBMS Industry Watch, November 16, 2015
Follow us on Twitter: @odbmsorg
##
“Orleans is an open-source programming framework for .NET that simplifies the development of distributed applications, that is, ones that run on many servers in a datacenter.”– Phil Bernstein.
I have interviewed, Phil Bernstein,a well known data base researcher and Distinguished Scientist at Microsoft Research, where he has worked for over 20 years. We discussed his latest project “Orleans”.
RVZ
Q1. With the project “Orleans” you and your team invented the “Virtual Actor abstraction”. What is it?
Phil Bernstein: Orleans is an open-source programming framework for .NET that simplifies the development of distributed applications, that is, ones that run on many servers in a datacenter. In Orleans, objects are actors, by which we mean that they don’t share memory.
In Orleans, actors are virtual in the same sense as virtual memory: an object is activated on demand, i.e. when one of its methods is invoked. If an object is already active when it’s invoked, the Orleans runtime will use its object directory to find the object and invoke it. If the runtime determines that the object isn’t active, the runtime will choose a server on which to activate the object, invoke the object’s constructor on that server to load its state, invoke the method, and update the object directory so it can direct future calls to the object.
Conversely, an object is deactivated when it hasn’t been invoked for some time. In that case, the runtime calls the object’s deactivate method, which does whatever cleanup is needed before freeing up the object’s runtime resources.
Q2. How is it possible to build distributed interactive applications, without the need to learn complex programming patterns?
Phil Bernstein: The virtual actor model hides distribution from the developer. You write code as if your program runs on one machine. The Orleans runtime is responsible for distributing objects across servers, which is something that doesn’t affect the program logic. Of course, there are performance and fault tolerance implications of distribution.
But Orleans is able to hide them too.
Q3. Building interactive services that are scalable and reliable is hard. How do you ensure that Orleans applications scale-up and are reliable?
Phil Bernstein: The biggest impediment to scaling out an app across servers is to ensure no server is a bottleneck. Orleans does this by evenly distributing the objects across servers. This automatically balances the load.
As for reliability, the virtual actor model makes this automatic. If a server fails, then of course all of the objects that were active on that server are gone. No problem. The Orleans runtime detects the server failure and knows which objects were active on the failed server. So the next time any of those objects is invoked, it takes its usual course of action, that is, it chooses a server on which to activate the object, loads the object, and invokes it.
Q4. What about the object’s state? Doesn’t that disappear when its server fails?
Phil Bernstein: Yes, of course all of the object’s main memory state is lost. It’s up to the object’s methods to save object state persistently, typically just before returning from a method that modifies the object’s state.
Q5. Is this transactional?
Phil Bernstein: No, not yet. We’re working on adding a transaction mechanism. Coming soon.
Q6. Can you give us an example of an Orleans application?
Phil Bernstein: Orleans is used for developing large-scale on-line games. For example, all of the cloud services for Halo 4 and Halo 5, the popular Xbox games, run on Orleans. Example object types are players, game consoles, game instances, weapons caches, and leaderboards. Orleans is also used for Internet of Things, communications, and telemetry applications. All of these applications are naturally actor-oriented, so they fit well with the Orleans programming model.
Q7. Why does the traditional three-tier architecture with stateless front-ends, stateless middle tier and a storage layer have limited scalability?
Phil Bernstein: The usual bottleneck is the storage layer. To solve this, developers add a middle tier to cache some state and thereby reduce the storage load. However, this middle tier loses the concurrency control semantics of storage, and now you have the hard problem of distributed cache invalidation. To enforce storage semantics, Orleans makes it trivial to express cached items as objects. And to avoid concurrency control problems, it routes requests to a single instance of each object, which is ordinarily single-threaded.
Also, a middle-tier cache does data shipping to the storage servers, which can be inefficient. With Orleans, you have an object-oriented cache and do function shipping instead.
Q8. How does Orleans differ from other Actor platforms such as Erlang and Akka?
Phil Bernstein: In Erlang and Akka, the developer controls actor lifecycle. You explicitly create an actor and choose the server on which it’s activated. Fixing the actor’s location at creation time prevents automating load balancing, actor migration, and server failure handling. For example, if an actor fails, you need code to catch the exception and resurrect the actor on another server. In Orleans, this is all automatic.
Another difference is the communications model. Orleans uses asynchronous RPC’s. Erlang and Akka use one-way messages.
Q9. Database people sometimes focus exclusively on the data model and query language, and don’t consider the problem of writing a scalable application on top of the database. How is Orleans addressing this issue?
Phil Bernstein: In a database-centric view, an app is a set of stored procedures with a stateless front-end and possibly a middle-tier cache. To scale out the app with this design, you need to partition the database into finer slices every time you want to add servers. By contrast, if your app runs on servers that are separate from the database, as it does with Orleans, you can add servers to scale out the app without scaling out the storage. This is easier, more flexible, and less expensive. For example, you can run with more app servers during the day when there’s heavier usage and fewer servers at night when the workload dies down. This is usually infeasible at the database server layer, since it would require migrating parts of the database twice a day.
Q10. Why did you transfer the core Orleans technology to 343 Industries ?
Phil Bernstein: Orleans was developed in Microsoft Research starting in 2009. Like any research project, after several years of use in production, it was time to move it into a product group, which can better afford the resources to support it. Initially, that was 343 Industries, the biggest Orleans user, which ships the Halo game. After Halo 5 shipped, the Orleans group moved to the parent organization, Microsoft Game Studios, which provides technology to Halo and many other Xbox games.
In Microsoft Research, we are still working on Orleans technology and collaborate closely with the product group. For example, we recently published code to support geo-distributed applications on Orleans, and we’re currently working on adding a transaction mechanism.
Q11. The core Orleans technology was also made available as open source in January 2015. Are developers actively contributing to this?
Phil Bernstein: Yes, there is a lot of activity, with contributions from developers both inside and outside Microsoft. You can see the numbers on GitHub – roughly 25 active contributors and over 25 more occasional contributors – with fully-tested releases published every couple of months. After the core .NET runtime and Roslyn compiler projects, Orleans is the next most popular .NET Foundation project on GitHub.
——————
Phil Bernstein is a Distinguished Scientist at Microsoft Research, where he has worked for over 20 years. Before Microsoft, he was a product architect and researcher at Digital Equipment Corp. and a professor at Harvard University. He has published over 150 papers and two books on the theory and implementation of database systems, especially on transaction processing and data integration, which are still the major areas of his work. He is an ACM Fellow, a winner of the ACM SIGMOD Innovations Award, a member of the Washington State Academy of Sciences and a member of the U.S. National Academy of Engineering. He received a B.S. degree from Cornell and M.Sc. and Ph.D. from University of Toronto.
Resources
Microsoft Research homepage for Orleans
Related Posts
On the Industrial Internet of Things. Interview with Leon Guzenda ODBMS Industry Watch, Published on 2016-01-28
Challenges and Opportunities of The Internet of Things. Interview with Steve Cellini ODBMS Industry Watch, Published on 2015-10-07
Follow ODBMS.org on Twitter: @odbmsorg
##
“Apart from security, the single biggest new challenges that the Industrial Internet of Things poses are the number of devices involved, the rate that many of them can generate data and the database and analytical requirements.” –Leon Guzenda.
I have interviewed Leon Guzenda, Chief Technical Marketing Officer at Objectivity. Topics of the interview are data analytics, the Industrial Internet of Things (IIoT), and ThingSpan.
RVZ
Q1. What is the difference between Big Data and Fast Data?
Leon Guzenda: Big Data is a generic term for datasets that are too large or complex to be handled with traditional technology. Fast Data refers to streams of data that must be processed or acted upon immediately once received.
If most, or all, of it is stored, it will probably end up as Big Data. Hadoop standardized the parallel processing approach for Big Data, and HDFS provided a resilient storage infrastructure. Meanwhile, Complex Event Processing became the main way of dealing with fast-moving streams of data, applying business logic and triggering event processing. Spark is a major step forward in controlling workflows that have streaming, batch and interactive elements, but it only offers a fairly primitive way to bridge the gap between the Fast and Big Data worlds via tabular RDDs or DataFrames.
ThingSpan, Objectivity’s new information fusion platform, goes beyond that. It integrates with Spark Streaming and HDFS to provide a dynamic Metadata Store that holds information about the many complex relationships between the objects in the Hadoop repository or elsewhere. It can be used to guide data mining using Spark SQL or GraphX and analytics using Spark MLlib.
Q2. Shawn Rogers, Chief Research Officer, Dell Statistica recently said in an interview: “A ‘citizen data scientist’ is an everyday, non-technical user that lacks the statistical and analytical prowess of a traditional data scientist, but is equally eager to leverage data in order to uncovering insights, and importantly, do so at the speed business”. What is your take on this?
Leon Guzenda: It’s a bit like the difference between amateur and professional astronomers.
There are far more data users than trained data scientists, and it’s important that the data users have all of the tools needed to extract value from their data. Things filter down from the professionals to the occasional users. I’ve heard the term “NoHow” applied to tools that make this possible. In other words, the users don’t have to understand the intricacy of the algorithms. They only need to apply them and interpret the results. We’re a long way from that with most kinds of data, but there is a lot of work in this area.
We are making advances in visual analytics, but there is also a large and rapidly growing set of algorithms that the tool builders need to make available. Users should be able to define their data sources, say roughly what they’re looking for and let the tool assemble the workflow and visualizers. We like the idea of “Citizen Data Scientists” being able to extract value from their data more efficiently, but let’s not forget that data blending at the front end is still a challenge and may need some expert help.
That’s another reason why the ThingSpan Metadata Store is important. An expert can describe the data there in terms that are familiar to the user. Applying the wrong analytical algorithm can produce false patterns, particularly when the data has been sampled inadequately. Once again, having an expert constrain those of particular algorithms to certain types of data can make it much more likely that the Citizen Data Scientists will obtain useful results.
Q3. Do we really need the Internet of Things?
Leon Guzenda: That’s a good question. It’s only worth inventing a category if the things that it applies to are sufficiently different from other categories to merit it. If we think of the Internet as a network of connected networks that share the same protocol, then it isn’t necessary to define exactly what each node is. The earliest activities on the Internet were messaging, email and file sharing. The WWW made it possible to set up client-server systems that ran over the Internet. We soon had “push” systems that streamed messages to subscribers rather than having them visit a site and read them. One of the fastest growing uses is the streaming of audio and video. We still haven’t overcome some of the major issues associated with the Internet, notably security, but we’ve come a long way.
Around the turn of the century it became clear that there are real advantages in connecting a wider variety of devices directly to each other in order to improve their effectiveness or an overall system. Separate areas of study, such as smart power grids, cities and homes, each came to the conclusion that new protocols were needed if there were no humans tightly coupled to the loop. Those efforts are now converging to the discipline that we call the Internet of Things (IoT), though you only have to walk the exhibitor hall at any IoT conference to find that we’re at about the same point as we were in the early NoSQL conferences. Some companies have been tackling the problems for many years whilst others are trying to bring value by making it easier to handle connectivity, configuration, security, monitoring, etc.
The Industrial IoT (IIoT) is vital, because it can help improve our quality of life and safety whilst increasing the efficiency of the systems that serve us. The IIoT is a great opportunity for some of the database vendors, such as Objectivity, because we’ve been involved with companies or projects tackling these issues for a couple of decades, notably in telecoms, process control, sensor data fusion, and intelligence analysis. New IoT systems generally need to store data somewhere and make it easy to analyze. That’s what we’re focused on, and why we decided to build ThingSpan, to leverage our existing technology with new open source components to enable real-time relationship and pattern discovery of IIoT applications.
Q4. What is special about the Industrial Internet of Things? And what are the challenges and opportunities in this area?
Leon Guzenda:. Apart from security, the single biggest new challenges that the IIoT poses are the number of devices involved, the rate that many of them can generate data and the database and analytical requirements. The number of humans on the planet is heading towards eight billion, but not all of them have Internet access. The UN expects that there will be around 11 billion of us by 2100. There are likely to be around 25 billion IIoT devices by 2020.
There is growing recognition and desire by organizations to better utilize their sensor-based data to gain competitive advantage. According to McKinsey & Co., organizations in many industry segments are currently using less than 5% of data from their sensors. Better utilization of sensor-based data could lead to a positive impact of up to $11.1 Trillion per year by 2025 through improved productivities.
Q5. Could you give us some examples of predictive maintenance and asset management within the Industrial IoT?
Leon Guzenda: Yes, neither use case is new nor directly the result of the IIoT, but the IIoT makes it easier to collect, aggregate and act upon information gathered from devices. We have customers building telecom, process control and smart building management systems that aggregate information from multiple customers in order to make better predictions about when equipment should be tweaked or maintained.
One of our customers provides systems for conducting seismic surveys for oil and gas companies and for helping them maximize the yield from the resources that they discover. A single borehole can have 10,000 sensors in the equipment at the site.
That’s a lot of data to process in order to maintain control of the operation and avoid problems. Replacing a broken drill bit can take one to three days, with the downtime costing between $1 million and $3.5 million. Predictive maintenance can be used to schedule timely replacement or servicing of the drill bit, reducing the downtime to three hours or so.
There are similar case studies across industries. The CEO of one of the world’s largest package transportation companies said recently that saving a single mile off of every driver’s route resulted in savings of $50 million per year! Airlines also use predictive maintenance to service engines and other aircraft parts to keep passengers safely in the air, and mining companies use GPS tracking beacons on all of their assets to schedule the servicing of vital and very costly equipment optimally. Prevention is much better than treatment when it comes to massive or expensive equipment.
Q6. What is ThingSpan? How is it positioned in the market?
Leon Guzenda: ThingSpan is an information fusion software platform, architected for performance and extensibility, to accelerate time-to-production of IoT applications. ThingSpan is designed to seat between streaming analytics platforms and Big Data platforms in the Fast Data pipeline to create contextual information in the form of transformed data and domain metadata from streaming data and static, historical data. Its main differentiators from other tools in the field are its abilities to handle concurrent high volume ingest and pathfinding query loads.
ThingSpan is built around object-data management technology that is battle-tested in data fusion solutions in production use with U.S. government and Fortune 1000 organizations. It provides out-of-the-box integration with Spark and Hadoop 2.0 as well as other major open source technologies. Objectivity has been bridging the gap between Big Data and Fast Data within the IIoT for leading government agencies and commercial enterprises for decades, in industries such as manufacturing, oil and gas, utilities, logistics and transportation, and telecommunications. Our software is embedded as a key component in several custom IIoT applications, such as management of real-time sensor data, security solutions, and smart grid management.
Q7. Graphs are hard to scale. How do you handle this in ThingSpan?
Leon Guzenda: ThingSpan is based on our scalable, high-performance, distributed object database technology. ThingSpan isn’t constrained to graphs that can be handled in memory, nor is it dependent upon messaging between vertices in the graph. The address space could be easily expanded to the Yottabyte range or beyond, so we don’t expect any scalability issues. The underlying kernel handles difficult tasks, such as pathfinding between nodes, so performance is high and predictable. Supplementing ThingSpan’s database capabilities with the algorithms available via Spark GraphX makes it possible for users to handle a much broader range of tasks.
We’ve also noted over the years that most graphs aren’t as randomly connected as you might expect. We often see clusters of subgraphs, or dandelion-like structures, that we can use to optimize the physical placement of portions of the graph on disk. Having said that, we’ve also done a lot of work to reduce the impact of supernodes (ones with extremely large numbers of connections) and to speed up pathfinding in the cases where physical clustering doesn’t work.
Q8. Could you describe how ThingSpan’s graph capabilities can be beneficial for use cases, such as cybersecurity, fraud detection and anti-money laundering in financial services, to name a few?
Leon Guzenda: Each of those use cases, particularly cybersecurity, deals with fast-moving streams of data, which can be analyzed by checking thresholds in individual pieces of data or accumulated statistics. ThingSpan can be used to correlate the incoming (“Fast”) data that is handled by Spark Streaming with a graph of connections between devices, people or institutions. At that point, you can recognize Denial of Service attacks, fraudulent transactions or money laundering networks, all of which will involve nodes representing suspicious people or organizations.
The faster you can do this, the more chance you have of containing a cybersecurity threat or preventing financial crimes.
Q9. Objectivity has traditionally focused on a relatively narrow range of verticals. How do you intend to support a much broader range of markets than your current base?
Leon Guzenda: Our base has evolved over the years and the number of markets has expanded since the industry’s adoption of Java and widespread acceptance of NoSQL technology. We’ve traditionally maintained a highly focused engineering team and very responsive product support teams at our headquarters and out in the field. We have never attempted to be like Microsoft or Apple, with huge teams of customer service people handling thousands of calls per day. We’ve worked with VARs that embed our products in their equipment or with system integrators that build highly complex systems for their government and industry customers.
We’re expanding this approach with ThingSpan by working with the open source community, as well as building partnerships with technology and service providers. We don’t believe that it’s feasible or necessary to suddenly acquire expertise in a rapidly growing range of disciplines and verticals. We’re happy to hand much of the service work over to partners with the right domain expertise while we focus on strengthening our technologies. We recently announced a technology partnership with Intel via their Trusted Analytics Platform (TAP) initiative. We’ll soon be announcing certification by key technology partners and the completion of major proof of concept ThingSpan projects. Each of us will handle a part of a specific project, supporting our own products or providing expertise and working together to improve our offerings.
———
Leon Guzenda, Chief Technical Marketing Officer at Objectivity
Leon Guzenda was one of the founding members of Objectivity in 1988 and one of the original architects of Objectivity/DB.
He currently works with Objectivity’s major customers to help them effectively develop and deploy complex applications and systems that use the industry’s highest-performing, most reliable DBMS technology, Objectivity/DB. He also liaises with technology partners and industry groups to help ensure that Objectivity/DB remains at the forefront of database and distributed computing technology.
Leon has more than five decades of experience in the software industry. At Automation Technology Products, he managed the development of the ODBMS for the Cimplex solid modeling and numerical control system.
Before that, he was Principal Project Director for International Computers Ltd. in the United Kingdom, delivering major projects for NATO and leading multinationals. He was also design and development manager for ICL’s 2900 IDMS database product. He spent the first 7 years of his career working in defense and government systems. Leon has a B.S. degree in Electronic Engineering from the University of Wales.
Resources
– What is data blending. By Oleg Roderick, David Sanchez, Geisinger Data Science, ODBMS.org, November 2015
- Industrial Internet of Things: Unleashing the Potential of Connected Products and Services. World Economic Forum. January 2015
Related Posts
– Can Columnar Database Systems Help Mathematical Analytics? by Carlos Ordonez, Department of Computer Science, University of Houston. ODBMS.org, 23 JAN, 2016.
–The Managers Who Stare at Graphs. By Christopher Surdak, JD. ODBMS.org, 23 SEP, 2015.
– From Classical Analytics to Big Data Analytics. by Peter Weidl, IT-Architect, Zürcher Kantonalbank. ODBMS.org,11 AUG, 2015
– Streamlining the Big Data Landscape: Real World Network Security Usecase. By Sonali Parthasarathy Accenture Technology Labs. ODBMS.org, 2 JUL, 2015.
Follow ODBMS.org on Twitter: @odbmsorg
##
“We have a profound ethical responsibility to design systems that have a positive impact on society, obey the law, and adhere to our highest ethical standards.”–Oren Etzioni.
On the impact of Artificial Intelligence (AI) on society, I have interviewed Oren Etzioni, Chief Executive Officer of the Allen Institute for Artificial Intelligence.
RVZ
Q1. What is the mission of the Allen Institute for AI (AI2)?
Oren Etzioni: Our mission is to contribute to humanity through high-impact AI research and engineering.
Q2. AI2 is the creation of Paul Allen, Microsoft co-founder, and you are the lead. What role Paul Allen has in AI2, and what is your responsibility?
Oren Etzioni AI2 is based on Paul Allen’s vision, and he leads our Board of Directors and is closely involved in setting our technical agenda. My job is to work closely with Paul and to recruit & lead our team to execute against our ambitious goals.
Q3. Driverless cars, digital Personal Assistants (e.g. Siri), Big Data, the Internet of Things, Robots: Are we on the brink of the next stage of the computer revolution?
Oren Etzioni: Yes, but never mistake a clear view for a short distance—it will take some time.
Q4. Do you believe that AI will transform modern life? How?
Oren Etzioni: Yes, within twenty years—every aspect of human life will transformed. Driving will become a hobby; medicine and science will be transformed by AI Assistants. There will even be robotic sex.
Q5. John Markoff in his book Machines of Loving Grace, reframes a question first raised more than half century ago, when the intelligent machine was born: Will we control these intelligent systems, or will they control us? What is your opinion on this?
Oren Etzioni: It is absolutely essential that we control the machines, and every indication is that we will be able to do so in the foreseeable future. I do worry about human motivations too. Someone said: I‘m not worried about robots deciding to kill people, I’m worried about politicians deciding robots should kill people.
Q6. If we delegate decisions to machines, who will be responsible for the consequences?
Oren Etzioni: Of course we are responsible. That is already true today when we use a car, when we fire a weapon—nothing will change in terms of responsibility. “My robot did it” is not an excuse for anything.
Q7. What are the ethical responsibilities of designers of intelligent systems?
Oren Etzioni: We have a profound ethical responsibility to design systems that have a positive impact on society, obey the law, and adhere to our highest ethical standards.
Q8. What are the current projects at AI2?
Oren Etzioni: We have four primary projects in active development at AI2.
- Aristo: Aristo is a system designed to acquire and store a vast amount of computable knowledge, then apply this knowledge to reason through and answer a variety of science questions from standardized exams for students in multiple grade levels. Aristo leverages machine reading, natural language processing, and diagram interpretation both to expand its knowledge base and to successfully understand exam questions, allowing the system to apply the right knowledge to predict or generate the right answers.
- Semantic Scholar: Semantic Scholar is a powerful tool for searching over large collections of academic papers. S2 leverages our AI expertise in data mining, natural-language processing, and computer vision to help researchers efficiently find relevant information. We can automatically extract the authors, venues, data sets, and figures and graphs from each paper and use this information to generate useful search and discovery experiences. We started with computer science in 2015, and we plan to scale the service to additional scientific areas over the next few years.
- Euclid: Euclid is focused on solving math and geometry problems. Most recently we created GeoS, an end-to-end system that uses a combination of computer vision to interpret diagrams, natural language processing to read and understand text, and a geometric solver to achieve 49 percent accuracy on official SAT test questions. We are continuing to expand and improve upon the different components of GeoS to improve its performance and expand its capabilities.
- Plato: Plato is focused on automatically generating novel knowledge from visual data, including videos, images, and diagrams, and exploring ways to supplement and integrate that knowledge with complementary text data. There are several sub-projects within Plato, including work on predicting the motion dynamics of objects in a given image, the development of a fully automated visual encyclopedia, and a visual knowledge extraction system that can answer questions about proposed relationships between objects or scenes (e.g. “do dogs eat ice cream?”) by using scalable visual verification.
Q9. What research areas are most promising for the next three years at AI2?
Oren Etzioni: We are focused on Natural Language, Machine learning, and Computer Vision.
Oren Etzioni: We have just launched Semantic Scholar —which leverages AI methods to revolutionize the search for computer science papers and articles.
Qx Anything else you with to add?
Oren Etzioni: Please see: AI will Empower us and please give us your feedback on Semantic Scholar.
————————
Dr. Oren Etzioni is Chief Executive Officer of the Allen Institute for Artificial Intelligence.
He has been a Professor at the University of Washington’s Computer Science department since 1991, receiving several awards including GeekWire’s Hire of the Year (2014), Seattle’s Geek of the Year (2013), the Robert Engelmore Memorial Award (2007), the IJCAI Distinguished Paper Award (2005), AAAI Fellow (2003), and a National Young Investigator Award (1993).
He was also the founder or co-founder of several companies including Farecast (sold to Microsoft in 2008) and Decide (sold to eBay in 2013), and the author of over 100 technical papers that have garnered over 23,000 citations.
The goal of Oren’s research is to solve fundamental problems in AI, particularly the automatic learning of knowledge from text. Oren received his Ph.D. from Carnegie Mellon University in 1991, and his B.A. from Harvard in 1986.
Books
MACHINES OF LOVING GRACE– The Quest for Common Ground Between Humans and Robots. By John Markoff.
Illustrated. 378 pp. Ecco/HarperCollins Publishers.
Big Data: A Revolution That Will Transform How We Live, Work and Think. Mayer-Schönberger, V. and Cukier, K. (2013)
Related Posts
– On Big Data and Society. Interview with Viktor Mayer-Schönberger, ODBMS Industry Watch, Published on 2016-01-08
——————
Follow ODBMS.org on Twitter: @odbmsorg.
##
“There is potentially too much at stake to delegate the issue of control to individuals who are neither aware nor knowledgable enough about how their data is being used to raise alarm bells and sue data processors.”–Viktor Mayer-Schönberger.
On Big Data and Society, I have interviewed Viktor Mayer-Schönberger, Professor of Internet Governance and Regulation at Oxford University (UK).
Happy New Year!
RVZ
Q1. Is big data changing people’s everyday world in a tangible way?
Viktor Mayer-Schönberger: Yes, of course. Most of us search online regularly. Internet search engines would not work nearly as well without Big Data (and those of us old enough to remember the Yahoo menus of the 1990s know how difficult it was then to find anything online). We would not have recommendation engines helping us find the right product (and thus reducing inefficient transaction costs), nor would flying in a commercial airplane be nearly as safe as it is today.
Q2. You mentioned in your recent book with Kenneth Cukier, Big Data: A Revolution That Will Transform How We Live Work and Think, that the fundamental shift is not in the machines that calculate data but in the data itself and how we use it. But what about people?
Viktor Mayer-Schönberger: I do not think data has agency (in contrast to Latour), so of course humans are driving the development. The point we were making is that the source of value isn’t the huge computing cluster or the smart statistical algorithm, but the data itself. So when for instance asking about the ethics of Big Data it is wrong to focus on the ethics of algorithms, and much more appropriate to focus on the ethics of data use.
Q3. What is more important people`s good intention or good data?
Viktor Mayer-Schönberger: This is a bit like asking whether one prefers apples or sunshine. Good data (being comprehensive and of high quality) reflects reality and thus can help us gain insights into how the world works. That does not make such discovery ethical, even though the discover is correct. Good intentions point towards an ethical use of data, which helps protect us again unethical data uses, but does not prevent false big data analysis. This is a long way of saying we need both, albeit for different reasons.
Q4. What are your suggestion for concrete steps that can be taken to minimize and mitigate big data’s risk?
Viktor Mayer-Schönberger: I have been advocating ex ante risk assessments of big data uses, rather than (as at best we have today) ex post court action. There is potentially too much at stake to delegate the issue of control to individuals who are neither aware nor knowledgable enough about how their data is being used to raise alarm bells and sue data processors. This is not something new. There are many areas of modern life that are so difficult and intransparent for individuals to control that we have delegated control to competent government agencies.
For instance, we don’t test the food in supermarkets ourselves for safety, nor do we crash-test cars before we buy them (or Tv sets, washing machines or microwave ovens), or run our own drug trials.
In all of these cases we put in place stringent regulation that has at its core a suitable process of risk assessment, and a competent agency to enforce it. This is what we need for Big Data as well.
Q5. Do you believe is it possible to ensure transparency, guarantee human freewill, and strike a better balance on privacy and the use of personal information?
Viktor Mayer-Schönberger: Yes, I do believe that. Clearly, today we are getting not enough transparency, and there aren’t sufficiently effective guarantees for free will and privacy in place. So we can do better. And we must.
Q6. You coined in your book the terms “propensity” and “fetishization” of data. What do you mean with these terms?
Viktor Mayer-Schönberger: I don’t think we coined the term “propensity”. It’s an old term denoting the likelihood of something happening. With the “fetishization of data” we meant the temptation (in part caused by our human bias towards causality – understanding the world around us as a sequence of causes and effects) to imbue the results of Big Data analysis with more meaning than they deserve, especially suggesting that they tell us why when they only tell us what.
Q7. Can big and open data be effectively used for the common good?
Viktor Mayer-Schönberger: Of course. Big Data is at its core about understanding the world better than we do today. I would not be in the academy if I did not believe strongly that knowledge is essential for human progress.
Q8. Assuming there is a real potential in using data–driven methods to both help charities develop better services and products, and understand civil society activity. What are the key lessons and recommendations for future work in this space?
Viktor Mayer-Schönberger: My sense is that we need to hope for two developments. First, that more researchers team up with decision makers in charities, and more broadly civil society organizations (and the government) to utilize Big Data to improve our understanding of the key challenges that our society is facing. We need to improve our understanding. Second, we also need decision makers and especially policy makers to better understand the power of Big Data – they need to realize that for their decision making data is their friend; and they need to know that especially here in Europe, the cradle of enlightenment and modern science, data-based rationality is the antidote to dangerous beliefs and ideologies.
Q9. What are your current areas of research?
Viktor Mayer-Schönberger: I have been working on how Big Data is changing learning and the educational system, as well as how Big Data changes the process of discovery, and how this has huge implications, for instance in the medical field.
——————
Viktor Mayer-Schönberger is Professor of Internet Governance and Regulation at Oxford University. In addition to the best-selling “Big Data” (with Kenneth Cukier), Mayer-Schönberger has published eight books, including the awards-winning “Delete: The Virtue of Forgetting in the Digital Age” and is the author of over a hundred articles and book chapters on the information economy. He is a frequent public speaker, and his work have been featured in (among others) New York Times, Wall Street Journal, Financial Times, The Economist, Nature and Science.
Books
Mayer-Schönberger, V. and Cukier, K. (2013) Big Data: A Revolution That Will Transform How We Live, Work and Think. John Murray.
Mayer-Schönberger, V. (2009) Delete – The Virtue of Forgetting in the Digital Age. Princeton University Press.
Related Posts
——————
Follow ODBMS.org on Twitter: @odbmsorg.
##
“Really, I would say this is indeed the essence of Big Data – being able to harness data from millions of endpoints whether they be devices or users, and optimizing outcomes for the individual, not just for the collective!”–Shilpa Lawande.
I have been following Vertica since their acquisition by HP back in 2011. This is my third interview with Shilpa Lawande, now Vice President at Hewlett Packard Enterprise, and responsible for strategic direction of the HP Big Data Platforms, including HP Vertica Analytic Platform.
The first interview I did with Shilpa was back on November 16, 2011 (soon after the acquisition by HP), and the second on July 14, 2014.
If you read the three interviews (see links to the two previous interviews at the end of this interview), you will notice how fast the Big Data Analytics and Data Platforms world is changing.
RVZ
Q1. What are the main technical challenges in offering data analytics in real time? And what are the main problems which occur when trying to ingest and analyze high-speed streaming data, from various sources?
Shilpa Lawande: Before we talk about technical challenges, I would like to point out the difference between two classes of analytic workloads that often get grouped under “streaming” or “real-time analytics”.
The first and perhaps more challenging workload deals with analytics at large scale on stored data but where new data may be coming in very fast, in micro-batches.
In this workload, challenges are twofold – the first challenge is about reducing the latency between ingest and analysis, in other words, ensuring that data can be made available for analysis soon after it arrives, and the second challenge is about offering rich, fast analytics on the entire data set, not just the latest batch. This type of workload is a facet of any use case where you want to build reports or predictive models on the most up-to-date data or provide up-to-date personalized analytics for a large number of users, or when collecting and analyzing data from millions of devices. Vertica excels at solving this problem at very large petabyte scale and with very small micro-batches.
The second type of workload deals with analytics on data in flight (sometimes called fast data) where you want to analyze windows of incoming data and take action, perhaps to enrich the data or to discard some of it or to aggregate it, before the data is persisted. An example of this type of workload might be taking data coming in at arbitrary times with granularity and keeping the average, min, and max data points per second, minute, hour for permanent storage. This use case is typically solved by in-memory streaming engines like Storm or, in cases where more state is needed, a NewSQL system like VoltDB, both of which we consider complementary to Vertica.
Q2. Do you know of organizations that already today consume, derive insight from, and act on large volume of data generated from millions of connected devices and applications?
Shilpa Lawande: HP Inc. and Hewlett Packard Enterprise (HPE) are both great examples of this kind of an organization. A number of our products – servers, storage, and printers all collect telemetry about their operations and bring that data back to analyze for purposes of quality control, predictive maintenance, as well as optimized inventory/parts supply chain management.
We’ve also seen organizations collect telemetry across their networks and data centers to anticipate servers going down, as well as to have better understanding of usage to optimize capacity planning or power usage. If you replace devices by users in your question, online and mobile gaming companies, social networks and adtech companies with millions of daily active users all collect clickstream data and use it for creating new and unique personalized experiences. For instance, user churn is a huge problem in monetizing online gaming.
If you can detect, from the in-game interactions, that users are losing interest, then you can immediately take action to hold their attention just a little bit longer or to transition them to a new game altogether. Companies like Game Show Network and Zynga do this masterfully using Vertica real-time analytics!
Really, I would say this is indeed the essence of Big Data – being able to harness data from millions of endpoints whether they be devices or users, and optimizing outcomes for the individual, not just for the collective!
Q3. Could you comment on the strategic decision of HP to enhance its support for Hadoop?
Shilpa Lawande: As you know HP recently split into Hewlett Packard Enterprise (HPE) and HP Inc.
With HPE, which is where Big Data and Vertica resides, our strategy is to provide our customers with the best end-to-end solutions for their big data problems, including hardware, software and services. We believe that technologies Hadoop, Spark, Kafka and R are key tools in the Big Data ecosystem and the deep integration of our technology such as Vertica and these open-source tools enables us to solve our customers’ problems more holistically.
At Vertica, we have been working closely with the Hadoop vendors to provide better integrations between our products.
Some notable, recent additions include our ongoing work with Hortonworks to provide an optimized Vertica SQL-on-Hadoop version for the Orcfile data format, as well as our integration with Apache Kafka.
Q4. The new version of HPE Vertica, “Excavator,” is integrated with Apache Kafka, an open source distributed messaging system for data streaming. Why?
Shilpa Lawande: As I mentioned earlier, one of the challenges with streaming data is ingesting it in micro- batches at low latency and high scale. Vertica has always had the ability to do so due to its unique hybrid load architecture whereby data is ingested into a Write Optimized Store in-memory and then optimized and persisted to a Read-Optimized Store on disk.
Before “Excavator,” the onus for engineering the ingest architecture was on our customers. Before Kafka, users were writing custom ingestion tools from scratch using ODBC/JDBC or staging data to files and then loading using Vertica’s COPY command. Besides the challenges of achieving the optimal load rates, users commonly ran into challenges of ensuring transactionality of the loads, so that each batch gets loaded exactly once even under esoteric error conditions. With Kafka, users get a scalable distributed messaging system that enables simplifying the load pipeline.
We saw the combination of Vertica and Kafka becoming a common design pattern and decided to standardize on this pattern by providing out-of-the-box integration between Vertica and Kafka, incorporating the best practices of loading data at scale. The solution aims to maximize the throughput of loads via micro-batches into Vertica, while ensuring transactionality of the load process. It removes a ton of complexity in the load pipeline from the Vertica users.
Q5.What are the pros and cons of this design choice (if any)?
Shilpa Lawande: The pros are that if you already use Kafka, much of the work of ingesting data into Vertica is done for you. Having seen so many different kinds of ingestion horror stories over the past decade, trust me, we’ve eliminated a ton of complexity that you don’t need to worry about anymore. The cons are, of course, that we are making the choice of the tool for you. We believe that the pros far outweigh any cons. 🙂
Q6. What kind of enhanced SQL analytics do you provide?
Shilpa Lawande: Great question. Vertica of course provides all the standard SQL analytic capabilities including joins, aggregations, analytic window functions, and, needless to say, performance that is a lot faster than any other RDBMS. 🙂 But we do much more than that. We’ve built some unique time-series analysis (via SQL) to operate on event streams such as gap-filling and interpolation and event series joins. You can use this feature to do common operations like sessionization in three or four lines of SQL. We can do this because data in Vertica is always sorted and this makes Vertica a superior system for time series analytics. Our pattern matching capabilities enable user path or marketing funnel analytics using simple SQL, which might otherwise take pages of code in Hive or Java.
With the open source Distributed R engine, we provide predictive analytical algorithms such as logistic regression and page rank. These can be used to build predictive models using R, and the models can be registered into Vertica for in- database scoring. With Excavator, we’ve also added text search capabilities for machine log data, so you can now do both search and analytics over log data in one system. And you recently featured a five-part blog series by Walter Maguire examining why Vertica is the best graph analytics engine out there.
Q7. What kind of enhanced performance to Hadoop do you provide?
Shilpa Lawande We see Hadoop, particularly HDFS, as highly complementary to Vertica. Our users often use HDFS as their data lake, for exploratory/discovery phases of their data lifecycle. Our Vertica SQL on Hadoop offering includes the Vertica engine running natively on Hadoop nodes, providing all the advanced SQL capabilities of Vertica on top of data stored in HDFS. We integrate with native metadata stores like HCatalog and can operate on file formats like Orcfiles, Parquet, JSON, Avro, etc. to provide a much more robust SQL engine compared to the alternatives like Hive, Spark or Impala, and with significantly better performance. And, of course, when users are ready to operationalize the analysis, they can seamlessly load the data into Vertica Enterprise which provides the highest performance, compression, workload management, and other enterprise capabilities for your production workloads. The best part is that you do not have to rewrite your reports or dashboards as you move data from Vertica for SQL on Hadoop to Vertica Enterprise.
Qx Anything else you wish to add?
Shilpa Lawande: As we continue to develop the Vertica product, our goal is to provide the same capabilities in a variety of consumption and deployment models to suit different use cases and buying preferences. Our flagship Vertica Enterprise product can be deployed on-prem, in VMWare environments or in AWS via an AMI.
Our SQL on Hadoop product can be deployed directly in Hadoop environments, supporting all Hadoop distributions and a variety of native data formats. We also have Vertica OnDemand, our data warehouse-as-a-service subscription that is accessible via a SQL prompt in AWS, HPE handles all of the operations such as database and OS software updates, backups, etc. We hope that by providing the same capabilities across many deployment environments and data formats, we provide our users the maximum choice so they can pick the right tool for the job. It’s all based on our signature core analytics engine.
We welcome new users to our growing community to download our Community Edition, which provides 1TB of Vertica on a three-node cluster for free, or sign-up for a 15-day trial of Vertica on Demand!
———
Shilpa Lawande is Vice President at Hewlett Packard Enterprise, responsible for strategic direction of the HP Big Data Platforms, including the flagship HP Vertica Analytic Platform. Shilpa brings over 20 years of experience in databases, data warehousing, analytics and distributed systems.
She joined Vertica at its inception in 2005, being one of the original engineers who built Vertica from ground up, and running the Vertica Engineering and Customer Experience teams for better part of the last decade. Shilpa has been at HPE since 2011 through the acquisition of Vertica and has held a diverse set of roles spanning technology and business.
Prior to Vertica, she was a key member of the Oracle Server Technologies group where she worked directly on several data warehousing and self-managing features in the Oracle Database.
Shilpa is a co-inventor on several patents on database technology, both at Oracle and at HP Vertica.
She has co-authored two books on data warehousing using the Oracle database as well as a book on Enterprise Grid Computing.
She has been named to the 2012 Women to Watch list by Mass High Tech, the Rev Boston 2015 list, and awarded HP Software Business Unit Leader of the year in 2012 and 2013. As a working mom herself, Shilpa is passionate about STEM education for Girls and Women In Tech issues, and co-founded the Datagals women’s networking and advocacy group within HPE. In her spare time, she mentors young women at Year Up Boston, an organization that empowers low-income young adults to go from poverty to professional careers in a single year.
Resources
- Uplevel Big Data analytics with HP Vertica – Part 1: Graph in a relational database? Seriously? by Walter Maguire
- Uplevel Big Data Analytics with Graph in Vertica – Part 2: Yes, you can write that in SQL by Walter Maguire
- Uplevel Big Data Analytics with Graph in Vertica – Part 3: Yes, you can make it go even faster by Walter Maguire
- Uplevel Big Data Analytics with Graph in Vertica – Part 4: It’s not your dad’s graph engine by Walter Maggiore
- Uplevel Big Data Analytics with Graph in Vertica – Part 5: Putting graph to work for your business by Walter Maguire
Related Posts
– On Column Stores. Interview with Shilpa Lawande. ODBMS Industry Watch,July 14, 2014
Follow ODBMS.org on Twitter: @odbmsorg
##
“Topdown cataloging and masterdata management tools typically require expensive data curators, and are not simple to use. This poses a significant threat to cataloging efforts since so much knowledge about your organization’s data is inevitably clustered across the minds of the people who need to question it and the applications they use to answer those questions.”–Gideon Goldin
I have interviewed Gideon Goldin, UX Architect, Product Manager at Tamr.
RVZ
Q1. What is “dark data”?
Gideon Goldin: Gartner refers to dark data as “the information assets organizations collect, process and store during regular business activities, but generally fail to use for other purposes (for example, analytics, business relationships and direct monetizing).” For most organizations, dark data comprises the majority of available data, and it is often the result of the constantly changing and unpredictable nature of enterprise data something that is likely to be exacerbated by corporate restructuring, M&A activity, and a number of external factors.
By shedding light on this data, organizations are better suited to make more datadriven, accurate business decisions.
Tamr Catalog, which is available as a free downloadable app, aims to do this, providing users with a view of their entire data landscape so they can quickly understand what was in the dark and why.
Q2. What are the main drawbacks of traditional topdown methods of cataloging or “master data management”?
Gideon Goldin: The main drawbacks are scalability and simplicity. When Yahoo, for example, started to catalog the web they employed some topdown approaches, hiring specialists to curate structured directories of information. As the web grew, however, their solution became less relevant and significantly more costly. Google, on the other hand, mined the web to understand references that exist between pages, allowing the relevance of sites to emerge from the bottomup. As a result, Google’s search engine was more accurate, easier to scale, and simpler.
Topdown cataloging and masterdata management tools typically require expensive data curators, and are not simple to use. This poses a significant threat to cataloging efforts since so much knowledge about your organization’s data is inevitably clustered across the minds of the people who need to question it and the applications they use to answer those questions. Tamr Catalog aims to deliver an innovative and vastly simplified method for cataloging your organization’s data.
Q3. Tamr recently opened a public Beta program Tamr Catalog for an enterprise metadata catalog. What is it?
Gideon Goldin: The Tamr Catalog Beta Program is an open invitation to testdrive our free cataloging software. We have yet to find an organization that is content with their current cataloging approaches, and we found that the biggest barrier to reform is often knowing where to start. Catalog can help: the goal of the Catalog Beta Program is to better understand how people want and need to collaborate around their data sources. We believe that an early partnership with the community will ensure that we develop useful functionality and thoughtful design.
Q4 What are the core functionality of Tamr Catalog?
Gideon Goldin: Tamr Catalog enables users to easily register, discover and organize their data assets.
Q5. How does it help simplify access to highquality data sets for analytics?
Gideon Goldin: Not surprisingly, people are biased to use the data sets closest to them. With Catalog, scientists and analysts can easily discover unfamiliar data setsdata sets, for example, that may belong to other departments or analysts. Catalog profiles and collects pointers to your sources, providing multifaceted and visual browsing of all data trivializing the search for any given set of data.
Q6. How does Tamr Catalog relate to the Tamr Data Unification Platform?
Gideon Goldin: Before organizations can unify their data, preparing it for improved analysis or management, they need to know what they have. Organizations often lack a good approach for this first (and repeating) step in data unification. We realized this quickly when helping large organizations begin their unification projects, and we even realized we lacked a satisfactory tool to understand our own data. Thus, we built Catalog as a part of the Tamr Data Unification Platform to illuminate your data landscape, such that people can be confident that their unification efforts are as comprehensive as possible.
Q7. What are the main challenges (technical and non technical) in achieving a broad adoption of a vendor and platform neutral metadata cataloging?
Gideon Goldin: Often the challenge isn’t about volume, it’s about variety. While a vendor neutral Catalog intends to solve exactly this, there remains a technical challenge in providing a flexible and elegant interface for cataloging dozens or hundreds of different types of data sets and the structures they comprise.
However, we find that some of the biggest (and most interesting) challenges revolve around organizational processes and culture. Some organizations have developed sophisticated but unsustainable approaches to managing their data, while others have become paralyzed by the inherently disorganized nature of their data. It can be difficult to appreciate the value of investing in these problems. Figuring out where to start, however, shouldn’t be difficult. This is why we chose to release a lightweight application free of charge.
Q8. Chief Data Officers (CDOs), data architects and business analysts have different requirements and different modes of collaborating on (shared) data sets. How do you address this in your catalog?
Gideon Goldin: The goal of cataloging isn’t cataloging, it’s helping CDOs identify business opportunities, empowering architects to improve infrastructures, enabling analysts to enrich their studies, and more. Catalog allows anyone to register and organize sources, encouraging open communication along the way.
Q9. How do you handle issues such as data protection, ownership, provenance and licensing in the Tamr catalog?
Gideon Goldin: Catalog allows users to indicate who owns what. Over the course of our Beta program, we have been fortunate enough to have over 800 early users of Catalog and have collected feedback about how our users would like to see data protection and provenance implemented in their own environments. We are eager to release new functionality to address these needs in the near future.
Q10. Do you plan to use the Tamr Catalog also for collecting data sets that can be used for data projects for the Common Good?
Gideon Goldin: We do know of a few instances of Catalog being used for such purposes, including projects that will build on the documenting of city and health data. In addition to our Catalog Beta Program, we are introducing a Community Developer Program, where we are eager to see how the community links Tamr Catalogs to new sources (including those in other catalogs), new analytics and visualizations, and ultimately insights. We believe in the power of open data at Tamr, and we’re excited to learn how we can help the Common Good.
—————————–
Gideon Goldin, UX Architect, Product Manager at Tamr.
Prior to Tamr, Gideon Goldin worked as a data visualization/UX consultant and university lecturer. He holds a Masters in HCI and a PhD in cognitive science from Brown University, and is interested in designing novel humanmachine experiences. You can reach Gideon on Twitter at @gideongoldin or email him at Gideon.Goldin at tamr.com.
Resources
– Download Free Tamr Catalog app.
-Tamr Catalog Developer Community
Online community where Tamr catalog users can comment, interact directly with the development team, and learn more about the software; and where developers can explore extending the tool by creating new data connectors.
– Gartner IT Glossary: Dark data
Related Posts
– Data for the Common Good. Interview with Andrea Powell. ODBMS Industry Watch, June 9, 2015
– Doubt and Verify: Data Science Power Tools By Michael L. Brodie, CSAIL, MIT
Follow ODBMs.org on Twitter: @odbmsorg